前沿数学基准测试揭示大模型数学能力不足,成功率不足2%
时间:2024-11-19 06:30:01 阅读:()
最近,一个名为FrontierMath的数学基准测试意外亮相,这使得许多大语言模型(LLM)在数学领域的能力被重新审视。这一基准测试由非营利机构Epoch AI推出,集合了全球超过60位杰出的数学家,包括国际数学奥林匹克的题目编写者和菲尔兹奖得主,旨在考察现代AI在复杂数学上的表现。
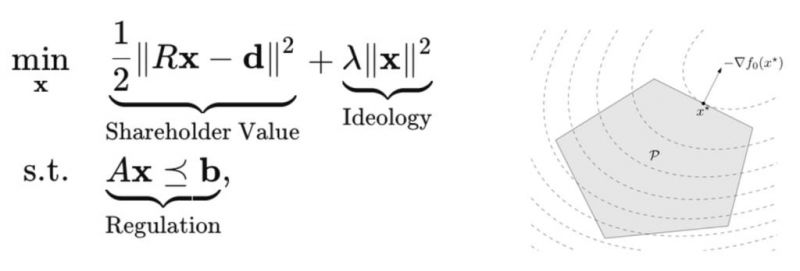
FrontierMath的设计理念
FrontierMath的题目涵盖了数论、代数几何、范畴论等多个数学分支,并且所有的问题都是全新且未发表的,以杜绝数据污染的风险。这个标准经过了严格的同行评审,确保了其科学性和公务性。更为重要的是,所有解法均为自动可验证的,这意味着模型需要提供确切的数学解答,而非简单的近似答案。
在这样严苛的标准下,大语言模型的表现实在令人失望。经过评估,所有参与的顶尖模型,包括GPT-4、Claude 3.5等,其成功率竟然低于2%。这一数据与传统的数学基准测试如GSM-8K和MATH形成了鲜明的对比,这些传统测试中的模型通常能够取得超过90%的准确率。
模型的真实能力
Epoch AI在分析这些大模型的表现时指出,当前流行的数学基准测试已被“刷烂”,即模型在训练过程中接触了大量的相似题目,导致其在特定条件下能够轻松获取高分。FrontierMath则试图打破这一现象,通过提供全新问题来真实考验模型的理解和推理能力。
这种设计方法在某种程度上反映了人工智能在处理数学问题时的局限性。前市面上的复杂题目虽然看似简单,但实际上AI在多步骤推理中保持逻辑一致性、深度理解问题本质和创造性解题策略的能力明显不足。
受访观点
在该基准测试推出后,Epoch AI还采访了多位菲尔兹奖得主,包括陶哲轩和蒂莫西·高尔斯,他们对AI的表现进行了深入的分析。陶哲轩指出,针对这些高难度问题,AI在未来几年内都难以实现有效解决。另一位菲尔兹奖得主也表示,能解出哪怕一道题目,都超出了他们目前的能力范围。
这样的观点不仅反映了人类数学家对AI能力的怀疑,也揭示了AI在数学领域存在的系统性局限性。这些局限性不仅限于数字计算能力,还包含对问题的深度理解以及逻辑推理的严谨性。
理解人类与AI的思维差异
而这种局限性让人联想到莫拉维克悖论,这种悖论显示了人类与计算机在直观上认为的任务难易程度之间的差距。一方面,计算机在处理国际象棋等封闭系统时表现出色,而另一方面,人们认为简单的生活技能却远远超出了机器的能力范畴。这解释了为何一些简单但极其复杂的任务在计算机眼里可能是遥不可及的。
随着技术的进步,如何为AI制定有效的数学能力评估标准成为了一个新的挑战。除了高效的多模式输入输出,还包括上下文的长短、连贯性、自主性等指标都将是未来评估AI能力的关键。
FrontierMath的推出不仅揭示了当前AI系统在数学能力上的局限性, 也让我对这些强大的模型产生了新的思考。尽管它们在许多领域表现卓越,但在面对真实的数学难题时,却显得捉襟见肘。这为研究AI的进一步发展提供了方向,同时也警示我们,机器智能的本质特征仍有待深入探讨。
在未来,我们希望更多的数学相关评测能引导AI的发展,激发其在复杂推理和创造性思维方面的潜力。只有通过这样的努力,才能期待AI在数学等前沿科学研究领域有所突破,更加贴近人类的认知方式。
转载请注明: https://m.xingzuo8.net/xinliceshi/2369.html